
Publication: A Primer on Reinforcement Learning in Medicine for Clinicians
Artificial intelligence (AI) is reshaping healthcare, and reinforcement learning (RL) stands at the forefront of this transformation. A recent article in npj Digital Medicine highlights RL’s potential to revolutionize clinical decision-making by dynamically adapting treatments to individual patients. Unlike traditional AI models, RL continuously learns from interactions with the patient, optimizing care strategies in real time. This ability to refine decisions as new data emerges makes RL particularly powerful for personalized medicine, where one-size-fits-all approaches often fall short.

The review introduces RL concepts to clinicians, outlining how these algorithms function and their potential applications across medical specialties. By simulating numerous possible treatment paths, RL can predict which interventions will yield the best outcomes based on a patient’s unique characteristics. This data-driven approach has already shown promise in managing chronic diseases, optimizing drug dosing, and even guiding robotic-assisted surgeries. As medical AI advances, RL could serve as a critical tool in reducing trial-and-error treatments and improving healthcare efficiency.
Despite its promise, integrating RL into clinical practice presents challenges. The complexity of medical environments, ethical considerations, and the need for extensive, high-quality data all pose significant hurdles. Moreover, ensuring that RL-driven recommendations align with medical guidelines and patient safety standards requires rigorous validation. Addressing these challenges will require collaboration between AI researchers, healthcare professionals, and policymakers to develop robust, transparent, and trustworthy RL systems.
| Offline RL algorithm | Conceptual framework | Key limitations |
|---|---|---|
| Behavioral Cloning (BC)31 | BC learns a policy by imitating expert behavior from a fixed dataset of expert demonstrations | BC can suffer from compounding errors when the learned policy diverges from the expert behavior, leading to poor generalization and performance in new situations |
| Q-Learning12 | Value-based off-policy method where the agent’s goal is to find an optimal policy by maximizing the expected value of the total rewards through iterative interactions with the environment when the model is not known. | Q-learning selects the action that yields the highest expected value which results in selected actions having consistently overestimated values. |
| Deep Q-Network (DQN)16 | DQN uses deep neural networks to represent the Q-function rather than a simple table of values. | DQN suffers from overestimation of action values and sensitivity to hyperparameters leading to computationally intensive training processes. |
| Double Deep Q-Network (DDQN)85 | The DDQN is an improvement over the DQN algorithm as it reduces the overestimation of action values by decoupling the selection and evaluation of actions, using two value function estimates by employing two separate neural networks. | DDQN also suffers from potential overestimation bias due to shared target and online networks and increased computational complexity from maintaining two separate networks. |
| Batch Constrained Q-Learning (BCQ)33 | It is as an off-policy algorithm that constrains exploration to improve policy learning and address overestimation bias in Q-learning. | BCQ’s learned policy is akin to robust imitation learning rather than true reinforcement learning when exploratory data is limited. |
| Conservative Q-Learning32 | CQL penalizes actions not well-supported by the dataset to mitigate overestimation bias, promoting safer policy learning in reinforcement learning scenarios. | CQL suffers from potential underestimation of action values due to conservative updates, leading to suboptimal policies, and increased computational complexity from the additional penalty term, impacting training efficiency. |
| Implicit Q-Learning (IQL)34 | IQL addresses the challenges of traditional Q-learning methods by leveraging implicit estimation techniques for improved policy optimization. It estimates the optimal action-value function indirectly, without explicitly modeling Q-values. | IQL learned policy depends on the distributions of actions. The performance regresses when the data distribution is skewed toward sub-optimal actions in specific states. |
| Conservative Policy Iteration (CPI)37 | CPI balances exploration and exploitation by penalizing deviations from observed behavior, aiming to converge to a risk-averse policy with improved performance in uncertain environments. | CPI suffers from conservative policies that may overly adhere to past behavior, potentially hindering exploration and innovation in dynamic environments. Additionally, CPI’s computational complexity can escalate with larger datasets, impacting scalability in real-world applications. |
| Behavior Regularized Off-Policy Q-Learning (BRAC)35 | BRAC introduces behavior regularization, which encourages the agent to prioritize actions that are consistent with the behavior observed in the dataset, leading to improved learning stability and performance. | The major limitations include difficulty in balancing exploration and exploitation, as well as challenges in effectively tuning the regularization parameter to achieve optimal performance across different environments and datasets. |
| Dueling Network Architecture (DNA)38 | The DNA architecture consists of two streams of fully connected layers that represent the value and advantage functions separately. It enables more efficient learning by allowing the agent to focus on valuable state information while independently estimating the advantage of different actions. | DNA can suffer from increased complexity and increased computational requirements including a lack of interpretability and potential issues with generalizability. |
| Soft Behavior-regularized Actor-Critic (SBAC)39 | SBAC incorporates behavior regularization by penalizing the policy for deviating from a behavior policy derived from past experience. This approach balances exploration and exploitation by leveraging previously collected data to improve learning efficiency. | Major limitations of SBAC include potential inefficiency in rapidly changing environments due to reliance on past behavior and the challenge of appropriately tuning the behavior regularization parameter, which can complicate the optimization process. |
| Adversarially Trained Actor-Critic (ATAC)40 | In ATAC, 2 networks are trained – actor and critic. Actor, which is responsible for selecting actions, is trained against a worst-case behavior policy estimated by the critic network. This adversarial training enhances the actor’s ability to perform well even under the most challenging conditions, promoting robustness and stability in learning. | ATAC suffers from need for increased computational complexity due to the adversarial training process, and potential challenges in effectively balancing the adversarial training objectives, which may affect convergence and performance stability. |
As reinforcement learning continues to evolve, it holds immense potential to reshape the future of medicine. By leveraging AI to make data-informed, personalized treatment decisions, clinicians can improve patient outcomes and optimize healthcare delivery. While hurdles remain, the progress in RL-driven medicine underscores the importance of interdisciplinary collaboration in bridging the gap between AI innovation and clinical application. The future of personalized medicine is unfolding, and reinforcement learning is poised to play a leading role.
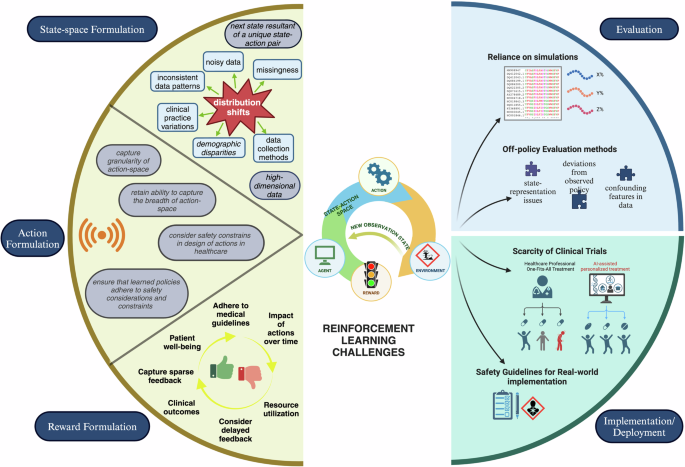
Source: Jayaraman, P., Desman, J., Sabounchi, M. et al. A Primer on Reinforcement Learning in Medicine for Clinicians. npj Digit. Med. 7, 337 (2024).